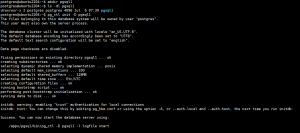
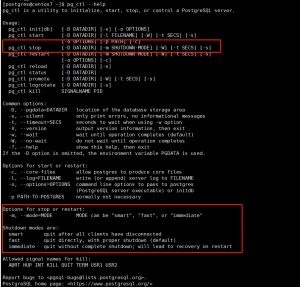
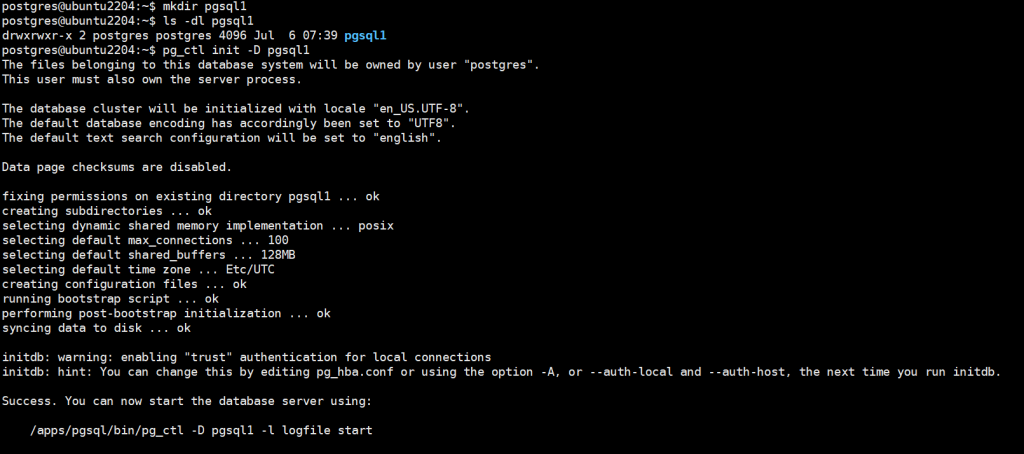
1、节点分类
单机节点 ES 存在单点问题,可以实现多机的集群,每个节点的角色有所不同。
ES的节点有三种:
- Master 节点
- ES集群中只有一个 Master 节点,用于控制整个集群的操作
- Master 节点负责增删索引,增删节点,shard分片的重新分配
- Master 主要维护Cluster State,包括节点名称,节点连接地址,索引名称和配置认息等
- Master 接受集群状态的变化并推送给所有节点,集群中各节点都有一份完整的集群状态信 息,都由master node负责维护
- Master 节点不需要涉及到文档级别的变更和搜索等操作
- 协调创建索引请求或查询请求,将请求分发到相关的node上。
- 当Cluster State有新数据产生后, Master 会将数据同步给其他 Node 节点
- Master节点通过超过一半的节点投票选举产生的
- 可以设置node.master: true 指定为是否参与Master节点选举, 默认true
- Data 节点
- 存储数据的节点即为 data 节点
- 当创建索引后,索引创建的数据会存储至某个数据节点
- Data 节点消耗内存和磁盘IO的性能比较大
- 配置node.data: true,默认为 true,即默认节点都是 data类型
- Coordinating 节点(协调)
- 处理请求的节点即为 coordinating 节点,该节点为所有节点的默认角色,不能取消
- coordinating 节点主要将请求路由到正确的节点处理。比如创建索引的请求会由 coordinating路由到 master 节点处理
- 当配置 node.master:false、node.data:false 则只充当 coordinating节点
2、集群选举
- ES集群的选举是由master-eligble(有资格的master节点)发起,当该节点发现当前节点不是master,并且该节点通过ZenDiscovery模块ping其他节点,得到超过mininum_master_nodes个节点无法连接master时,就会发起选举
- 选举时,优先选举ClusterStateVersion最大的Node节点,如果ClusterStateVersion相同,则选举ID最小的Node
- ClusterStateVersion是集群的状态版本号,每一次集群选举ClusterStateVersion都会更新,因此最大的ClusterStateVersion是与原有集群数据最接近或者是相同的,这样就尽可能的避免数据丢失。
- Node的ID是在第一次服务启动时随机生成的,直接选用最小ID的Node,主要是为了选举的稳定性,尽量少的出现选举不出来的问题。
- 每个集群中只有一个Master节点
- 每个集群中损坏的节点不能超过集群一半以上,否则集群将无法提供服务
3、ES 集群分片和副本
3.1、分片 Shard
ES 中存储的数据可能会很大,有时会达到PB级别
基于性能和容量等原因,可以将一个索引数据分割成多个小的分片,再将每个分片分布至不同的节点,从而实现数据的分布存储,实现性能和容量的水平扩展
在读取时,可以实现多节点的并行读取,提升性能
除此之外,如果一个分片的主机宕机,也不影响其它节点分片的读取
横向扩展即增加服务器,当有新的Node节点加入到集群中时,集群会动态的重新进行分配和负载
例如原来有两个Node节点,每个节点上有3个分片,即共6个分片,如果再添加一个node节点到集群中,
集群会动态的将此6个分片分配到这三个节点上,最终每个节点上有两个分片。
7,X 默认每个索引只有一个分片
3.2、副本 Replication
将一个索引分成多个分片,仍然存在数据的单点问题,可以对每一个分片进行复制生成副本,即备份,实现数据的高可用
ES的分片分为主分片(primary shard)和副本分片(复制replica shard),而且通常分布在不同节点
主分片实现数据读写,副本分片只支持读
每个数据分片只有一个主分片,而副本分片可以有多个,比如:一个副本,即有一个备份
7,X 默认每个索引只有一个副本分片
4、ES集群故障转移
故障转移指的是,当集群中有节点发生故障时,ES集群会进行自动修复
![图片[1]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-18.png)
假设由3个节点的ES集群组成,其中一个节点宕机
ES集群的故障转移流程如下:
- 重新选举
- node3 节点宕机,导致 node3 的原有的P2和R1分片丢失
- node1 和 node2 发现 node3 无法响应
- 一段时间后会发起 master 选举,比如这里选择 node1 为 master 节点;此时集群状态变为 Red状态
![图片[2]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-19.png)
- 主分片调整
- 新的Master节点 node1 发现在原来在node3上的主分片 P2 未分配,将 node2 上的 R2 提升为主分片
- 此时所有的主分片都正常分配,但1和2分片没有副本分片,集群状态变为 Yellow状态
- 副本分片调整
- node1 将 P1 和 P2 主分片重新生成新的副本分片 R1、R2,此时集群状态变为 Green
- 修复好node3节点后,自动将各个分片均匀分配
![图片[3]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-20.png)
![图片[4]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-21.png)
5、ES 文档路由
5.1、ES 文档路由原理
在ES 中,通过如下的公式计算文档对应的分片存储到哪个节点
shard = hash(routing) % number_of_primary_shards
# hash 算法保证将数据均匀分散在分片中
# routing 是一个可变参数,默认是文档id,也可以自定义。
# number_of_primary_shards 主分片数
# 注意:该算法与主分片数相关,一但确定后便不能更改主分片![图片[5]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-22.png)
可以发送请求到集群中的任一节点。每个节点都知道集群中任一文档位置, 每个节点都有能力接收请求,再接将请求转发到真正存储数据的节点上
5.2、ES 文档创建流程
![图片[6]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-23.png)
- 客户端向协调节点 Node1 发送新建索引文档或者删除索引文档请求。
- Node1节点使用文档的 _id 确定文档属于分片 0 。
- 因为分片 0 的主分片目前被分配在 Node 3 上,请求会被转发到 Node 3
- Node3 在主分片上面执行创建或删除请求
- Node3 执行如果成功,它将请求并行转发到 Node1 和 Node2 的副本分片上。
- 一旦所有的副本分片都报告成功,Node3 将向协调节点Node1 报告成功
- 协调节点Node1 客户端报告成功。在客户端收到响应时,文档变更已经在主分片和所有副本分片执行完成
5.3、ES 文档读取流程
可以从主分片或者从其它任意副本分片读取文档 ,读取流程如下图所示:
![图片[7]-Elasticsearch 集群工作原理-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2023/01/image-24.png)
- 客户端向 Node1 发送读取请求。
- 节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。
- 在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在这种情况下,它将请求转发到 Node2 。
- Node2 将文档返回给 Node1 ,然后将文档返回给客户端。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END