![图片[1]-MySQL 架构-李佳程的个人主页](http://www.lijiach.com/wp-content/uploads/2022/11/image-109.png)
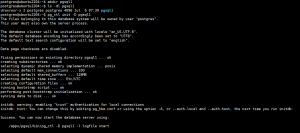
MySQL是C/S 架构的,connectors是连接器;可供Native C API、JDBC、ODBC、NET、PHP、Perl、Python、Ruby、Cobol等连接mysql;ODBC叫开放数据库(系统)互联,open database connection;JDBC是主要用于java语言利用较为底层的驱动连接数据库;
以上这些,站在编程角度可以理解为连入数据库管理系统的驱动,站在mysql角度称作专用语言对应的链接器。
任何链接器连入mysql以后,mysql是单进程多线程模型的,因此,每个用户连接,都会创建一个单独的连接线程;其实mysql连接也有长短连接两种方式,使用mysql客户端连入数据库后,直到使用quit命令才退出,可认为是长连接;使用mysql中的-e选项,在mysql客户端向服务器端申请运行一个命令后则立即退出,也就意味着连接会立即断开;所以,mysql也支持长短连接类似于两种类型;所以,用户连入mysql后,创建一个连接线程,完成之后,能够通过这个连接线程完成接收客户端发来的请求,为其处理请求,构建响应报文并发给客户端;由于是单进程模型,就意味着必须要维持一个线程池,需要一个线程池来管理这众多线程是如何对众多客户端的并发请求,完成并发响应的,组件connection pool就是实现这样功能;
connection pool对于mysql而言,它所实现的功能,包括:
authentication认证,用户发来的账号密码是否正确要完成认证功能;
thread reuse线程重用功能,一般当一个用户连接进来以后要用一个线程来响应它,而后当用户退出这个线程有可能并非被销毁,而是把它清理完以后,重新收归到线程池当中的空闲线程中去,以完成所谓的线程重用;
connection limit 线程池的大小决定了连接并发数量的上限,例如,最多容纳100线程,一旦到达此上限后续到达的连接请求则只能排队或拒绝连接;
check memory用来检测内存,caches实现线程缓存;整个都属于线程池的功能.当用户请求之后,通过线程池建立一个用户连接,这个线程一直存在,然后用户就通过这个会话,发送对应的SQL语句到服务器端。
服务器收到SQL语句后,要对语句完成执行,首先要能理解sql语句需要有sql解释器或叫sql接口sql interface就可理解为是整个mysql的外壳,就像shell是linux操作系统的外壳一样;用户无论通过哪种链接器发来的基本的SQL请求,当然,事实上通过native C API也有发过来的不是SQL 请求,而仅仅是对API中的传递参数后的调用;不是SQL语句不过都统统理解为sql语句罢了;
对SQL而言分为DDL 和DML两种类型,但是无论哪种类型,提交以后必须交给内核,让内核来运行,在这之前必须要告诉内核哪个是命令,哪个是选项,哪些是参数,是否存在语法错误等等;因此,这个整个SQL 接口就是一个完完整整的sql命令的解释器,并且这个sql接口还有提供完整的sql接口应该具备的功能,比如支持所谓过程式编程,支持代码块的实现像存储过程、存储函数,触发器、必要时还要实现部署一个关系型数据库应该具备的基本组件例如视图等等,其实都在sql interface这个接口实现的;SQL接口做完词法分析、句法分析后,要分析语句如何执行让parser解析器或分析器实现。
parser是专门的分析器,这个分析器并不是分析语法问题的,语法问题在sql接口时就能发现是否有错了,一个语句没有问题,就要做执行分析,所谓叫查询翻译,把一个查询语句给它转换成对应的能够在本地执行的特定操作;比如说看上去是语句而背后可能是执行的一段二进制指令,这个时候就完成对应的指令,还要根据用户请求的对象,比如某一字段查询内容是否有对应数据的访问权限,或叫对象访问权限;在数据库中库、表、字段、字段中的数据有时都称为object,叫一个数据库的对象,用户认证的通过,并不意味着就能一定能访问数据库上的所有数据,所以说,mysql的认证大概分为两过程都要完成,第一是连入时需要认证账号密码是否正确这是authentication,然后,验证成功后用户发来sql语句还要验证用户是否有权限获取它期望请求获取的数据;这个称为object privilege,这一切都是由parser分析器进行的。
分析器分析完成之后,可能会生成多个执行树,这意味着为了能够达到访问期望访问到的目的,可能有多条路径都可实现,就像文件系统一样可以使用相对路径也可使用绝对路径;它有多种方式,在多种路径当中一定有一个是最优的,类似路由选择,因此,优化器就要去衡量多个访问路径中哪一个代价或开销是最小的,这个开销的计算要依赖于索引等各种内部组件来进行评估;而且这个评估的只是近似值,同时还要考虑到当前mysql内部在实现资源访问时统计数据,比如,根据判断认为是1号路径的开销最小的,但是众多统计数据表明发往1号路径的访问的资源开销并不小,并且比3号路径大的多,因此,可能会依据3号路径访问;这就是所谓的优化器它负责检查多条路径,每条路径的开销,然后评估开销,这个评估根据内部的静态数据,索引,根域根据动态生成的统计数据来判定每条路径的开销大小,因此这里还有statics;一旦优化完成之后,还要生成统计数据,这就是优化器的作用;如果没有优化器mysql执行语句是最慢的,其实优化还包括一种功能,一旦选择完一条路径后,例如用户给的这个命令执行起来,大概需要100个开销,如果通过改写语句能够达到同样目的可能只需要30个开销;于是,优化器还要试图改写sql语句;所以优化本身还包括查询语句的改写;一旦优化完成,接下来就交给存储引擎完成
mysql是插件式存储引擎,它就能够替换使用选择多种不同的引擎,MyISAM是MySQL 经典的存储引擎之一,InnoDB是由Innobase Oy公司所开发,2006年五月由甲骨文公司并购提供给MySQL的,NDB主要用于MySQL Cluster 分布式集群环境,archive做归档的等等,还有许多第三方开发的存储引擎;存储引擎负责把具体分析的结果完成对磁盘上文件路径访问的转换,数据库中的行数据都是存储在磁盘块上的,因此存储引擎要把数据库数据映射为磁盘块,并把磁盘块加载至内存中;进程实现数据处理时,是不可能直接访问磁盘上的数据的,因为它没有权限,只有让内核来把它所访问的数据加载至内存中以后,进程在内存中完成修改,由内核再负责把数据存回磁盘;对于文件系统而言,数据的存储都是以磁盘块方式存储的,但是,mysql在实现数据组织时,不完全依赖于磁盘,而是把磁盘块再次组织成更大一级的逻辑单位,类似于lvm中的PE或LE的形式;其实,MySQL的存储引擎在实现数据管理时,也是在文件系统之上布设文件格式,对于文件而言在逻辑层上还会再次组织成一个逻辑单位,这个逻辑单位称为mysql的数据块datablock 一般为16k ,对于关系型数据库,数据是按行存储的;一般一行数据都是存储在一起的,因此,MySQL 在内部有一个datablock,在datablock可能存储一行数据,也可能存放了n行数据;将来在查询加载一行数据时,内核会把整个一个数据数据块加载至内存中,而mysql存储引擎,就从中挑出来某一行返回给查询者,是这样实现的;所以整个存储是以datablock在底层为其最终级别的.
事实上,整个存取过程,尤其是访问比较热点的数据,也不可能每一次当用户访问时或当某SQL语句用到时再临时从磁盘加载到内存中,因此,为了能够加上整个性能,mysql的有些存储引擎可以实现,把频繁访问到的热点数据,统统装入内存,用户访问、修改时直接在内存中操作,只不过周期性的写入磁盘上而已,比如像InnoDB,所以caches和buffers组件就是实现此功能的;MySQL为了执行加速,因为它会不断访问数据,而随计算机来说io是最慢的一环,尤其是磁盘io,所以为了加速都载入内存中管理;这就需要MySQL 维护cache和buffer缓存或缓冲;这是由MySQL 服务器自己维护的;有很多存储引擎自己也有cache和buffer。
一个数据库提供了3种视图,物理视图就是看到的对应的文件系统存储为一个个的文件,MySQL的数据文件类型,常见的有redo log重做日志,undo log撤销日志,data是真正的数据文件,index是索引文件,binary log是二进制日志文件,error log错误日志,query log查询日志,slow query log慢查询日志,在复制架构中还存在中继日志文件,跟二进制属于同种格式;这是mysql数据文件类型,也就是物理视图;逻辑视图这是在mysql接口上通过存储引擎把mysql文件尤其是data文件,给它映射为一个个关系型数据库应该具备组成部分,比如表,一张表在底层是一个数据文件而已,里面组织的就是datablock,最终映射为磁盘上文件系统的block,然后再次映射为本地扇区的存储,但是整个mysql需要把他们映射成一个二维关系表的形式,需要依赖sql接口以及存储引擎共同实现;所以,把底层数据文件映射成关系型数据库的组件就是逻辑视图;DBA 就是关注内部组件是如何运作的,并且定义、配置其运作模式,而链接器都是终端用户通过链接器的模式进入数据库来访问数据;数据集可能非常大,每一类用户可能只有一部分数据的访问权限,这个时候,最终的终端用户所能访问到的数据集合称作用户视图;
为了保证MySQL运作还提供了管理和服务工具,例如:备份恢复工具,安全工具,复制工具,集群服务,管理、配置、迁移、元数据等工具。